
Nanobot é um “OpenClaw destilado”: mantém o loop de agente, memória e skills, mas com muito menos código e recursos, enquanto PicoClaw é a versão ainda mais extrema focada em hardware barato em Go.
Visão geral rápida
- OpenClaw: framework completo, pesado, com gateway multi‑canal, UI web, multi‑agente, roteamento de modelos, etc.
- Nanobot: reimplementação ultra‑leve em Python, ~3.5–4k linhas (≈99% menor que Claw/OpenClaw), mesma filosofia de “IA que faz coisas”, mas focado em simplicidade e auto‑hospedagem fácil.
- PicoClaw: refactor em Go a partir do Nanobot, pensado para rodar em 10MB de RAM em hardware de 10 dólares, bootando em <1s.
Diferenças Nanobot vs OpenClaw vs PicoClaw
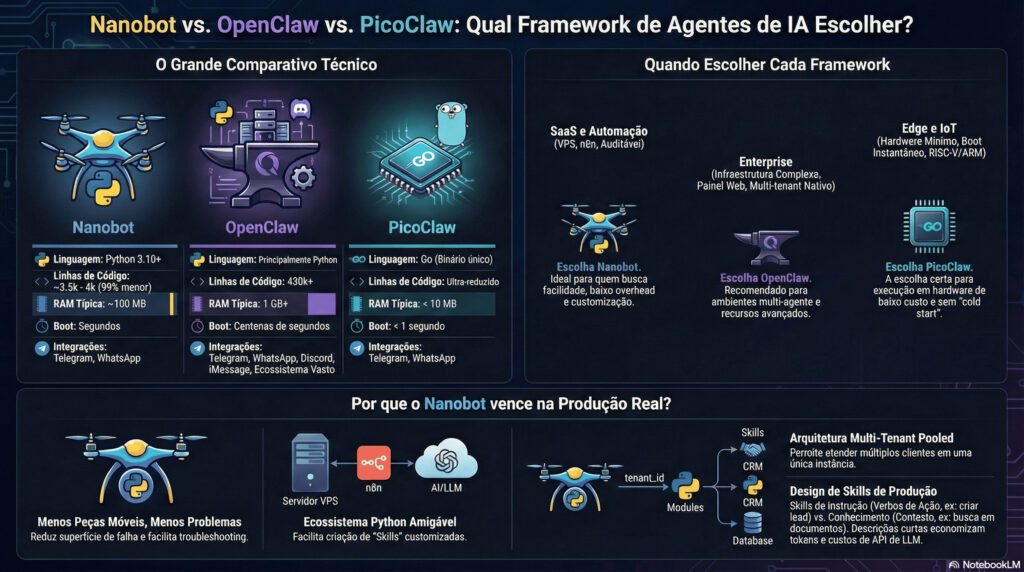
Na sua situação (dev de automação, n8n, WhatsApp, VPS), o Nanobot tende a ser o meio‑termo ideal: menos overhead que OpenClaw, mas sem as limitações de hardware extremo do PicoClaw.
Vantagens específicas do Nanobot
- Leve, mas completo: loop de agente, memória persistente, tarefas agendadas (cron), sub‑agentes de background, múltiplos provedores de LLM e integrações de chat.
- Infra simples: roda em qualquer OS que suporte Python 3.10+, com ~100MB de RAM e só precisa de internet + um provedor de LLM (OpenRouter, OpenAI, etc.).
- Código pequeno e auditável: ~3.5k linhas, fácil entender, debugar e customizar (bem diferente do monolito OpenClaw).
- 100% open source (MIT): pode forkar, adaptar para sua stack (n8n, webhooks internos, automações).
Quando comparado ao OpenClaw, você perde a UI web complexa, alguns recursos enterprise e o ecossistema gigantesco, mas ganha velocidade de desenvolvimento e menos dor de cabeça de manutenção.
Skills, plugins e Mission Control (conceito)
A nomenclatura varia por projeto, mas a estrutura é parecida:
- Skills/plugins (Nanobot):
- São módulos Python que expõem “ferramentas” (funções com schema) para o agente, por exemplo: chamar uma API, rodar um script, acessar um banco, etc.
- O agente escolhe a skill via tool‑calling do LLM, parecido com OpenClaw.
- Plugins/skills no OpenClaw:
- Grande ecossistema de “skills” e “nodes” (integração com WhatsApp, CRM, automação, etc.), configurados em arquivos de config e UI.
- “Mission control” (idéia):
- Em OpenClaw costuma ser a combinação de gateway + painel web e configurações de roteamento de agentes/modelos, que funcionam como centro de comando.
- No Nanobot, esse “mission control” tende a ser mais CLI + arquivos de configuração, com menos camadas, mas mesma lógica: um processo que orquestra agentes, tarefas e skills.
Na prática, para você, “mission control” = onde você define: modelos, chaves, skills habilitadas, agenda de tarefas e canais (Telegram/WhatsApp etc.).
Guia definitivo: instalação do Nanobot (Docker, local e VPS)
Vou focar em um fluxo padrão: Linux (Ubuntu/Debian), com opção Docker (mais simples) e instalação bare‑metal, pensando em deploy em VPS ou servidor local.
1. Pré‑requisitos
- Python 3.10+ instalado (se for modo bare‑metal).
- Git (para clonar o repositório).
- Docker + Docker Compose (se preferir container).
- Chaves de API de pelo menos um LLM (OpenRouter, OpenAI, etc.).
Exemplo de instalação de base em Ubuntu:
bashsudo apt update
sudo apt install -y git python3 python3-venv python3-pip docker.io docker-compose
2. Instalação via Docker (recomendada para produção)
- Clonar o repositório Nanobot:bash
git clone https://github.com/HKUDS/nanobot.git cd nanobot
- Verificar se há
Dockerfile/compose pronto; muitos templates de deploy já existem (Railway etc.).
Se existirdocker-compose.yml, basta:bashdocker-compose up -dou, com Docker puro:bashdocker build -t nanobot . docker run -d --name nanobot \ -p 8000:8000 \ -e OPENROUTER_API_KEY="sua_chave" \ nanobot(Substitua variáveis pelos providers que for usar.) - Configurar persistência:
3. Instalação local (bare‑metal, dev)
- Clonar e entrar:bash
git clone https://github.com/HKUDS/nanobot.git cd nanobot
- Criar venv e instalar dependências:bash
python3 -m venv .venv source .venv/bin/activate pip install --upgrade pip pip install -r requirements.txt(Oupip install .se o projeto estiver empacotado.) - Configurar variáveis de ambiente (exemplo para OpenRouter):bash
export OPENROUTER_API_KEY="sua_chave" export NANOBOT_MODEL="openrouter/algum-modelo"O site do projeto cita suporte multi‑LLM, incluindo OpenRouter e vLLM para modelos locais. - Rodar o agente:bash
python -m nanobotou o entrypoint documentado (python main.py,nanobot serve, etc., conforme o README).
4. Integração com canais (Telegram, WhatsApp)
Pelos materiais públicos, Nanobot suporta integrações com Telegram e WhatsApp, de forma similar ao OpenClaw.
Em geral, o padrão é:
- Criar bot no Telegram (BotFather) e pegar o token.
- Configurar no
.envouconfig.ymldo Nanobot algo como:textTELEGRAM_BOT_TOKEN=123456:abc... TELEGRAM_ENABLED=true - Para WhatsApp, usar uma camada gateway (por exemplo, cliente oficial ou bridge) com credenciais e apontar webhooks para o Nanobot.
A doc oficial costuma fornecer exemplos de configuração de cada canal, então vale seguir o trecho de “Interactive conversations through multiple platforms”.
Configuração avançada: modelos, skills, agendamentos
1. Roteamento de modelos
Tanto OpenClaw quanto Nanobot são model‑agnostic, mas OpenClaw tem um roteador robusto com fallback, múltiplos providers e perfis por canal.
No Nanobot, um setup avançado razoável é:
- Definir um modelo “principal” (fronteira) para orquestração.
- Definir modelos mais baratos/rápidos para tarefas simples (heartbeat, rotinas, sumarização).
Estrutura típica de config (pseudocode):
textmodels:
orchestrator:
provider: openrouter
model: anthropic/claude-3-opus
fast:
provider: openrouter
model: openai/gpt-4.1-mini
local:
provider: vllm
model: llama-3-8b-instruct
E no código de skills, você escolhe qual “perfil” usar em cada chamada.
2. Skills / plugins customizados
Fluxo típico para criar uma skill no Nanobot (exemplo prático para n8n):
- Criar um módulo, ex.:
skills/n8n_webhook.py. - Definir uma função com assinatura clara (nome, parâmetros) que será registrada como ferramenta do agente.
- Registrar a skill num registry/manifest que o Nanobot lê em startup.
Pseudocódigo:
python# skills/n8n_webhook.py
import requests
def call_n8n_workflow(workflow_url: str, payload: dict) -> dict:
resp = requests.post(workflow_url, json=payload, timeout=30)
resp.raise_for_status()
return resp.json()
E no arquivo de registry (depende do formato real do projeto, mas algo assim):
textskills:
- name: call_n8n_workflow
module: skills.n8n_webhook
description: "Dispara um workflow n8n via webhook"
args_schema:
workflow_url: string
payload: object
A partir daí, o LLM consegue escolher essa ferramenta quando precisar acionar automações externas.
3. Tarefas agendadas (cron / heartbeat)
Nanobot e PicoClaw citam suporte a tarefas agendadas e “heartbeat” para sub‑agentes.
Geralmente funciona assim:
- Você define um arquivo (por ex.
CRON.yamlou similar) com tarefas:- cron expression
- skill/função a ser chamada
- parâmetros
Exemplo conceitual:
textjobs:
- name: monitorar_leads
schedule: "*/5 * * * *" # a cada 5 minutos
skill: call_n8n_workflow
args:
workflow_url: "https://seu-n8n/webhook/leads"
payload:
source: "nanobot"
O processo principal do Nanobot lê esse arquivo e dispara as skills conforme o cron.
4. Segurança básica
Algumas boas práticas inspiradas em OpenClaw e PicoClaw:
- Rodar o Nanobot com usuário sem privilégios, dentro de chroot/container quando possível.
- Restringir acesso a filesystem (workspace específico), especialmente se você expuser skills de leitura/escrita de arquivos.
- Validar cuidadosamente skills que executam comandos de sistema ou chamam APIs sensíveis.
- Limitar tokens de contexto e número de passos por tarefa para evitar loops e consumo exagerado.
Quando usar Nanobot, OpenClaw ou PicoClaw
- Você quer entender e customizar tudo, com pouco overhead → Nanobot.
- Você precisa de uma infra de agente “all‑in‑one” com painel, multi‑tenant, multi‑gateway, ecosistema grande → OpenClaw.
- Você quer rodar numa caixinha RISC‑V/ARM baratíssima, com 10MB de RAM, ultra‑otimizado → PicoClaw.
Por que desenvolvedores preferem Nanobot sobre OpenClaw e PicoClaw em produção real — trade-offs ocultos de performance e escalabilidade
Desenvolvedores costumam preferir Nanobot em produção “real” porque ele entrega 80–90% do que OpenClaw e PicoClaw oferecem, com muito menos complexidade operacional, menor RAM base e uma superfície de falha bem menor. Em cargas típicas de SaaS e automação (não edge extremo), esses fatores pesam mais que os micro‑ganhos de performance bruta ou de features avançadas dos outros dois.
Arquitetura e impacto na performance
- Nanobot é uma reimplementação ultra‑leve do “espírito” do OpenClaw em ~3,5–4k linhas de Python, declaradamente ~99% menor que o código original do Claw/OpenClaw. Isso reduz o número de componentes residentes em memória, simplifica o loop do agente e diminui o overhead entre receber mensagem, chamar LLM e executar skills.
- OpenClaw vem de uma base de centenas de milhares de linhas (Clawdbot/Moltbot), com gateway multi‑canal, UI web, router avançado de modelos, memória sofisticada e ecossistema grande de skills, o que implica múltiplos serviços, workers e processos rodando juntos. Em produção isso se traduz em maior uso de RAM/CPU mesmo em baixa carga, e mais hops internos entre camadas.
- PicoClaw refatora a lógica do Nanobot em Go com foco extremo em footprint: inicia em <1s, roda em <10MB de RAM e um binário único voltado a hardware de 10 dólares. Em troca, ele abre mão de boa parte da “gordura” de ecossistema e abstrações para caber nesse alvo ultra‑restrito.
Trade-offs ocultos de escalabilidade
Olhando só para benchmarks simples, parece que “OpenClaw é mais poderoso” e “PicoClaw é mais leve”, mas em produção aparecem alguns custos escondidos:
- Overhead de features do OpenClaw
- Cada camada extra (gateway, mission control web, router complexo, orquestração multi‑agente) adiciona latência, pontos de contenção e requisitos de sincronização de estado.
- Ao crescer o tráfego, não é só “escalar pods”: é escalar UI, banco de memória, workers especializados, filas internas e manter todos saudáveis, o que aumenta custo operacional e risco de gargalos em partes que não aparecem em um benchmark local.
- Limites práticos do PicoClaw em cenários grandes
- A otimização de PicoClaw é direcionada para rodar bem em hardware ridiculamente barato e com boot instantâneo, não para multi‑tenant complexo ou painéis ricos.
- Em um SaaS multi‑tenant em nuvem, 10MB de RAM por instância deixa de ser o gargalo, e pesa mais ter log, observabilidade, integrações ricas e um ecossistema maduro de libs e plugins, onde a base Python do Nanobot costuma ser mais vantajosa.
Por que Nanobot costuma ganhar em produção “normal”
Menos moving parts = menos problemas
- O Nanobot foi desenhado explicitamente como uma alternativa “que você consegue entender” ao OpenClaw: menos código, menos serviços, deploy simples (um app Python ou um container) e foco em um único agente com skills.
- Essa simplicidade se traduz em: bootstrap mais rápido, menos pontos de falha, troubleshooting mais direto e curva de aprendizado bem menor para o time inteiro (não só para quem estudou a fundo o framework).
Performance suficiente com overhead pequeno
- Em cenários comuns (1–N VPS, LLM via API, uso intensivo de I/O externo), o gargalo não é o tempo de boot do binário ou 50MB a mais de RAM, mas sim: latência da API de LLM, APIs internas, banco e filas.
- O Nanobot mantém o loop de agente, memória e skills com um processo leve em Python, o suficiente para saturar as chamadas de LLM antes que o próprio runtime vire gargalo, desde que se faça scaling horizontal básico (múltiplas instâncias atrás de um load balancer).
Integrações e ecosistema Python
- O projeto enfatiza uso de múltiplos provedores de LLM (OpenRouter, OpenAI, vLLM para modelos locais), o que encaixa bem junto de libs Python para HTTP, bancos, mensageria etc.
- Para automação e SaaS típicos (n8n, webhooks, CRMs, bancos), Python continua sendo “língua franca”, então criar skills e extensões no Nanobot tende a ser mais rápido do que encaixar tudo no modelo ultra‑enxuto de PicoClaw ou no ecossistema mais carregado de OpenClaw.
Impactos práticos em produção
Trade-offs ao crescer a carga
- Até algumas dezenas/centenas de RPS reais (considerando chamadas de LLM)
- Nanobot normalmente aguenta bem com poucas instâncias horizontais, mantendo arquitetura simples.
- OpenClaw pode estar “subutilizado”, com mais infra do que o necessário.
- Quando surgem requisitos enterprise fortes (multi‑tenant avançado, múltiplos agentes especializados com coordenação, UI rica para time de operações)
- OpenClaw começa a fazer mais sentido, porque já traz boa parte desses componentes integrados.
- Porém o custo de operação (SRE, observabilidade, upgrades) cresce junto.
- Edge / hardware restrito ou boot instantâneo
- PicoClaw domina: boot <1s, <10MB de RAM, perfeito para devices baratos e ambientes serverless muito agressivos em cold start.
- Em cloud “normal” (VPS, containers com recursos folgados), esse ganho raramente compensa abrir mão da flexibilidade do ecossistema Python do Nanobot.
Quando escolher cada um (produção real)
- Nanobot
- SaaS de automação, bots de atendimento, integrações com n8n/CRMs, rodando em VPS ou Kubernetes leve, onde simplicidade, debuggabilidade e custo operacional importam mais que features enterprise exóticas.
- OpenClaw
- Plataformas de agentes complexas, multi‑agente, multi‑canal, com times dedicados de MLOps/SRE dispostos a operar uma stack mais pesada para ganhar painel, roteamento avançado e ecossistema maior.
- PicoClaw
- Casos de edge/IoT, experimentos em hardware baratíssimo ou cenários onde “caber em 10MB e subir em <1s” é requisito de projeto, não um nice‑to‑have.
Arquiteturas de referência com Nanobot
Em vez de começar por Kubernetes e malabarismo de microserviços, faz mais sentido pensar em “como as mensagens chegam até o Nanobot, como saem, e onde vivem estado e conhecimento”. A partir disso, dá para montar alguns padrões de arquitetura reaproveitáveis que funcionam bem em produção real, inclusive em cenários multi‑tenant.
Arquitetura básica: Nanobot + n8n em 1–2 VPS
Nesta configuração, a prioridade é simplicidade operacional, mantendo espaço para crescer depois.
Componentes típicos:
- VPS 1 (Core de IA): Nanobot rodando como serviço (Docker ou bare‑metal), com acesso às APIs de LLM (OpenRouter, OpenAI, modelos locais via vLLM se precisar).
- VPS 2 (Orquestração e integrações): n8n ou outro orquestrador, banco de dados (Postgres/MySQL), filas leves (Redis/Rabbit) e serviços auxiliares (webhooks, APIs internas).
- Canais de entrada: Telegram/Discord conectados diretamente ao Nanobot, e canais mais sensíveis (como WhatsApp Business oficial) chegando via webhooks do próprio orquestrador ou de serviços intermediários.
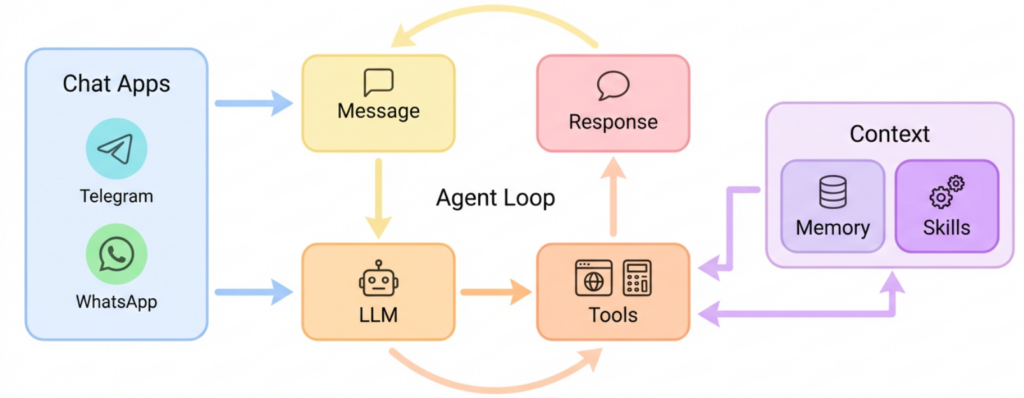
Fluxo de alto nível:
- Mensagem chega por um canal (Telegram, web app, webhook interno).
- Um gateway leve normaliza a mensagem, anexa um identificador de sessão/usuário/tenant e encaminha para o Nanobot via HTTP/gRPC.
- O Nanobot processa a conversa, chama skills quando necessário (por exemplo, uma skill que dispara um workflow no n8n).
- A resposta volta para o gateway, que envia de volta para o canal correto, preservando o contexto de sessão.
Esse padrão lembra o “pipe único de mensagens” usado em arquiteturas multi‑bot com rótulos de clientId/userId/chatId, mostrado em discussões de multi‑tenant de agentes. A vantagem é manter o Nanobot como “cérebro” relativamente puro, enquanto a cola de integrações e persistência mais pesada fica no n8n e no banco.
Arquitetura multi‑tenant “pooled” com Nanobot
Quando a mesma instância de Nanobot precisa servir vários clientes (SaaS multi‑tenant), o contexto de tenant precisa existir desde o primeiro contato da sessão, não apenas na borda da API.
Padrão típico:
- Binding de tenant na criação de sessão: no login ou no primeiro webhook, o sistema resolve o tenant e grava esse contexto num token de sessão ou num registro de sessão em banco (por exemplo,
session_id → tenant_id, user_id, canal). - Contexto compartilhado e imutável: todas as chamadas para o Nanobot carregam o
tenant_idnum header ou payload padronizado, que o agente usa para escolher memória, base de conhecimento e configurações específicas. - Acesso a dados só via ferramentas: o Nanobot nunca fala direto com o banco de dados multi‑tenant; em vez disso, chama skills/tooling que já aplicam as regras de tenant no nível de query/API.
Esse modelo “pooled” é o clássico: múltiplos tenants compartilham o mesmo compute, mas os dados e a configuração são sempre filtrados por tenant no nível de ferramenta, como recomendado em guias de multi‑tenant para agentes. Para o Nanobot, isso vira uma convenção de design de skills (por exemplo, toda skill recebe tenant_id e nunca acessa recursos globais sem filtragem).
Arquitetura híbrida: tenants grandes com instância dedicada
Conforme alguns clientes crescem (volume, criticidade, requisitos de compliance), fica natural evoluir para um modelo híbrido: alguns tenants continuam “pooled”, outros recebem instância dedicada do Nanobot.
Nesse modelo:
- Tenants pequenos/medianos continuam atendidos por uma ou poucas instâncias compartilhadas do Nanobot, com isolamento lógico via contexto de sessão e ferramentas tenant‑aware.
- Tenants grandes ganham instâncias exclusivas (VPS ou cluster próprio), às vezes até com LLMs locais/vLLM e bancos dedicados, operando em modo “siloed” no jargão de multi‑tenancy.
A principal vantagem é ter um caminho de evolução claro: começar simples com uma instância pooled, depois “promover” tenants estratégicos para instâncias dedicadas sem reescrever o core do Nanobot, apenas replicando a mesma stack com configs e bancos separados.
Multi‑cliente e multi‑interface na camada de UI
Outra dimensão de arquitetura é como o mesmo Nanobot atende múltiplos clientes e interfaces (web, CLI, terceiros) mantendo estado compartilhado e consistente.
Boas práticas derivadas de experiências com UIs de MCP/agent frameworks:
- Manter o “estado verdadeiro” (memória, dados de sessão, conhecimento) no servidor, não no cliente, e tratar web/CLI/apps de terceiros apenas como frontends.
- Padronizar um contrato de “sessão + identidade” que todos os clientes usam, evitando que cada canal invente seu próprio modelo de contexto.
- Garantir que qualquer nova interface (por exemplo, painel web próprio do seu SaaS) simplesmente consuma o mesmo endpoint de conversação do Nanobot, com os mesmos campos de tenant e usuário.
Design de skills de produção
Skills são o ponto onde o Nanobot “encosta” em sistemas reais; é aí que aparecem bugs, vazamentos de dados e custos desnecessários de token/contexto se o design for ingênuo. Um bom design de skills reaproveita lições de ecossistemas maduros como OpenClaw e plugins/skills de outros agentes, mas simplificados para a realidade do Nanobot.
Superfície da skill: clara, pequena e estável
Experiências com OpenClaw mostram que cada skill carrega um custo fixo de tokens no prompt, e que uma superfície de skills inchada prejudica performance e aumenta a complexidade cognitiva do modelo.
Boas práticas:
- Preferir poucas skills bem desenhadas em vez de dezenas de variações que fazem quase a mesma coisa.
- Manter nome, descrição e parâmetros da skill curtos e precisos; documentações de skills recomendam descrições compactas e informativas para minimizar overhead de prompt.
- Tratar a interface (nome, schema de parâmetros, contrato de retorno) como “API pública” e evitar quebrá‑la com frequência; ecossistemas de skills bem‑sucedidos em OpenClaw e em diretórios públicos seguem essa disciplina.
Tipos de skill: instrução vs conhecimento
Alguns playbooks e guias de plugins para agentes modernos distinguem explicitamente skills de “ação” (instruction‑type) e skills de “conhecimento” (knowledge‑type), com recomendações de uso diferentes.
Aplicando isso ao Nanobot:
- Skills de instrução:
- São chamadas diretamente em resposta a intenções do usuário (ex: “criar lead no CRM”, “enviar e‑mail”, “disparar workflow no n8n”).
- Devem ser verbos claros e síncronos sempre que possível, com retorno concreto de sucesso/erro.
- Skills de conhecimento:
- Dão ao agente acesso a bases de conhecimento, documentação, relatórios, logs, etc., geralmente via busca/consulta.
- Não deveriam ser expostas como “comandos” diretos do usuário, e sim usadas internamente pelo agente quando precisa de contexto adicional.
Esse modelo casa bem com o princípio de progressive disclosure: primeiro o modelo vê apenas uma lista compacta de skills disponíveis; detalhes maiores (documentação, exemplos) são acessados só quando necessário, preservando tokens e foco.
Configuração, segredos e ambiente
Documentação de skills do OpenClaw e guias de plugins enfatizam a ideia de declarar dependências de ambiente por skill (API keys, configs, bins presentes) e permitir que plugins tragam suas próprias pastas de skills.
Para skills do Nanobot em produção:
- Centralizar chaves e configs por skill em um arquivo de configuração ou sistema de secrets, em vez de hard‑code ou
.envdispersos. - Permitir que “plugins internos” (conjuntos de skills da sua própria empresa) registrem múltiplas skills de uma vez, em uma convenção de diretório clara.
- Carregar as configs no início de cada execução do agente (ou por sessão) e restaurar o ambiente depois, evitando vazamentos de variáveis globais, como sugerido pelo mecanismo de injeção de ambiente por run do OpenClaw.
Padronização de erros, timeouts e retries
Playbooks de desenvolvimento de plugins para agentes destacam a importância de padronizar erros e ter checklists de validação para evitar comportamentos inconsistentes. Em skills de produção, isso vira alguns padrões simples:
- Toda skill deve ter timeouts claros em chamadas externas (HTTP, DB, filas) e retornar erros estruturados em vez de estourar exceções cruas.
- Retentativas (retries) só devem ser aplicadas a erros transitórios (time‑out, 5xx), e sempre com limites e backoff, para não transformar um problema de rede em tempestade de requisições.
- Logs de tool call precisam registrar input sanitizado, latência e tipo de erro para cada execução, o que facilita debugar o comportamento do agente em produção.
Token economy e impacto das skills no prompt
A documentação de skills do OpenClaw mede explicitamente o custo em caracteres/tokens de cada skill ativada na lista que vai para o prompt do modelo. Isso traz algumas lições diretas aplicáveis ao Nanobot:
- Cada skill ativada tem um custo fixo de tokens em toda chamada do agente, mesmo que não seja usada naquela conversa.
- Descrições longas, nomes prolixos ou campos redundantes multiplicam esse custo, principalmente quando o número de skills cresce.
- Um design “minimalista” de metadados (nome curto, descrição objetivo, sem textos enciclopédicos no cabeçalho) libera tokens para o que realmente importa: contexto de usuário e dados de negócio.
Uma estratégia prática é manter um conjunto “core” de skills sempre ligadas e mover skills mais específicas para conjuntos carregados sob demanda, dependendo do tenant, canal ou tipo de tarefa.
Exemplos de categorias de skills úteis em produção
Explorando diretórios públicos de skills de OpenClaw dá para ver alguns padrões de categorias que fazem sentido replicar no Nanobot.
Algumas categorias comuns:
- Integração com sistemas internos: skills que falam com CRMs, ERPs, bancos, sistemas de ticket, etc., sempre respeitando contexto de tenant.
- Operações técnicas: skills para monitorar logs, checar status de serviços, inspecionar filas, executar diagnósticos básicos em APIs internas.
- Produtividade: skills para resumir documentos, gerar relatórios, organizar tarefas, extrair dados estruturados de textos.
- Orquestração de outros agentes/ferramentas: skills que disparam outros agentes, workflows no n8n ou pipelines, agindo como “control plane” de automações.
Para o Nanobot, selecionar poucas skills muito bem feitas em cada uma dessas categorias costuma ser mais eficiente do que tentar replicar de cara todo o ecossistema gigante do OpenClaw.
Conclusão
No fim das contas, Nanobot, OpenClaw e PicoClaw não estão competindo pela mesma coroa: cada um cristaliza uma filosofia diferente de “agente em produção”. OpenClaw representa o extremo do poder e da abrangência, com uma arquitetura rica em camadas, skills e integrações; PicoClaw leva essa arquitetura ao limite da eficiência de hardware, comprimindo o conceito de agente num binário Go que roda em menos de 10 MB de RAM; já o Nanobot destila o “kernel” do agente em ~4.000 linhas de Python, entregando o loop de agente, memória e ferramentas com 99% menos código que o ecossistema original.
Para um time que quer colocar agentes em produção de forma sustentável, a principal mensagem deste artigo é que simplicidade arquitetural e clareza de código são vantagens competitivas tão importantes quanto throughput bruto ou quantidade de features. Nanobot tende a ser o sweet spot onde desenvolvedores conseguem entender o que está rodando, adaptar rapidamente às necessidades do negócio, projetar skills realmente de produção e escalar horizontalmente sem herdar toda a complexidade de uma plataforma enterprise como o OpenClaw, nem as restrições de um runtime ultra‑minimalista como o PicoClaw. A escolha “certa” deixa de ser uma questão de hype e passa a ser uma decisão de arquitetura: qual desses três encaixa melhor no seu modelo de risco, equipe, faturamento e visão de longo prazo para IA em produção.